Lorsqu’il s’agit d’introduire des variables aléatoires comme l’échelle, la rotation, la position et bien d’autres choses, Houdini excelle dans l’exercice.
C’est pourtant un point qui semble difficile à aborder pour bon nombre de débutants.
En générale le néophyte « se précipite » sur le Node Copy Stamp.
Surtout parce que c’est la technique qui ressort le plus souvent lorsque l’on fait des recherches concernant les copies aléatoire sur Google ou Youtube.
Toutefois, c’est loin d’être la technique idéale et pour moi j’irais même jusqu’à dire qu’il ne faut pas utiliser ce Node. Voilà pourquoi :
- Son « langage » et ses variables sont isolés du reste de Houdini ce qui fait que vous devez apprendre une syntaxe propre à ce Node…
- Du fait que ce c’est pas une boucle clairement identifiée, son fonctionnement est confusant.
- Il autorise moins de chose qu’une boucle For-each, notamment lorsqu’il s’agit de contrôler le retour des itérations dans la boucle. Autrement dit, avec un Node Copy Stamp, on agit sur toutes les itérations ou aucune.
- Et surtout, c’est un Node peu performant qui peut très vite alourdir votre setup.
Jusqu’à peu, sur la documentation Houdini, il était même noté que le Copy Stamp était un Node déprécié et qu’il fallait se tourner vers les boucles For-each. Cependant, cette remarque semble avoir disparue à la sortie de Houdini 18.
Comme vous l’aurez compris, il n’y a que des avantages à utiliser les boucles For-each à la place du Copy Stamp.
Leur « langage’ est commun à tout Houdini, elles offrent une très grande souplesse, elles sont plus performante et de plus on peut les compiler pour obtenir encore plus de performance.
Connaissances pré-requise
Avant d’attaquer les copies aléatoires avec les boucles For-each, il est nécessaire de connaître et de savoir utiliser trois fonctions d’Houdini, à savoir la fonction rand(), la fonction fit() et la fonction detail(). Je vous explique leur utilisation un peu plus bas.
Dans l’exemple que je vous présente un peu plus loin dans cet article nous utiliserons ces expressions en HScript mais il se trouve que les fonctions rand() et fit() ont des fonctionnements et des syntaxes parfaitement similaire que ce soit en HScript ou en VEX :
- Documentation de la fonction rand() en HScript.
- Documentation de la fonction rand() en VEX.
- Documentation de la fonction fit() en HScript.
- Documentation de la fonction fit() en VEX
La fonction detail, elle, diffère légèrement si elle est utilisée en VEX ou en HScript, nous nous concentrerons donc sur son utilisation en HScript.
La fonction random rand()
Rien de bien sorcier, cette fonction renvoi un nombre décimal compris entre 0 et 1.
La seul chose à bien comprendre c’est qu’elle requiert une valeur en entrée. Ce n’est pas un générateur autonome de nombre aléatoire entre 0 et 1, pas de valeur à traiter en argument = pas de nombre random.
La fonction fit()
Cette fonction prend une plage de valeurs en entrée et la fait correspondre à une autre plage de valeurs en sortie.
Par exemple, si vous avez une série de nombres compris entre -10 et 10, vous pouvez demander à la fonction fit de redistribuer les valeurs entre 0 et 1 à la sortie. La proportion entre les nombres est bien entendu conservé.
Dans notre cas, nous allons nous servir de la fonction rand() pour traiter une suite de nombre aléatoire généré par la fonction random afin qu’elle corresponde à une plage de valeurs souhaitées.
Imaginer que vous voulez qu’un objet tourne aléatoirement de +/- 45° suivant un axe lors de sa copie. Nous nous servirons alors de la fonction fit() comme cela :
fit("valeur_aléatoire", 0, 1, -45, 45)Qui peut se traduire en langage courante par : « Transforme la variable aléatoire en entrée qui est comprise entre 0 et 1 pour la faire correspondre à des valeurs comprises entre -45 et 45.
NOTE : Vous pouvez aussi utiliser la fonction fit01() qui est un peu plus automatisée puisqu’elle ne prend en entrée que des valeurs comprises entre 0 et 1. Fonctionne donc très bien avec un nombre généré par la fonction rand()
fit01("valeur_aléatoire", -45, 45)C’est juste une question de goût (et de mémoire !), le résultat est strictement le même.
La fonction detail()
Cette fonction permet de lire et de retourner la valeur d’un attribut de classe detail sur une shape donnée.
Voyons en détails ses arguments :

- surface node : tout simplement la shape que l’on souhaite lire, requiert un string de type « ../foreach_begin1_metadata1 » par exemple, OU « -1 » si on utilise une Spare Input.
- attrib_name : le nom de l’attribut que l’on veut lire, requiert également un string, par exemple « otherpos ».
- attrib_index : l’index de l’attribut que l’on souhaite lire.
Par exemple, si « otherpos » est un attribut de type vecteur, il possède trois composantes, « otherpos.x », « otherpos.y », « otherpos.z ». « otherpos.x » est sur l’index 0, « otherpos.y », sur l’index 1 « otherpos.z » sur l’index 2.
Création du setup de copies aléatoires
Configurer la boucle.
Voila le setup de départ, une box de 10 x 10 en Primitive Type « Points », Axe divisions 3 x 3 x 3 (26 points donc), une boucle For-each Point, un Copy to Points dans la boucle et un Pig Head en mode Difficulty Easy.
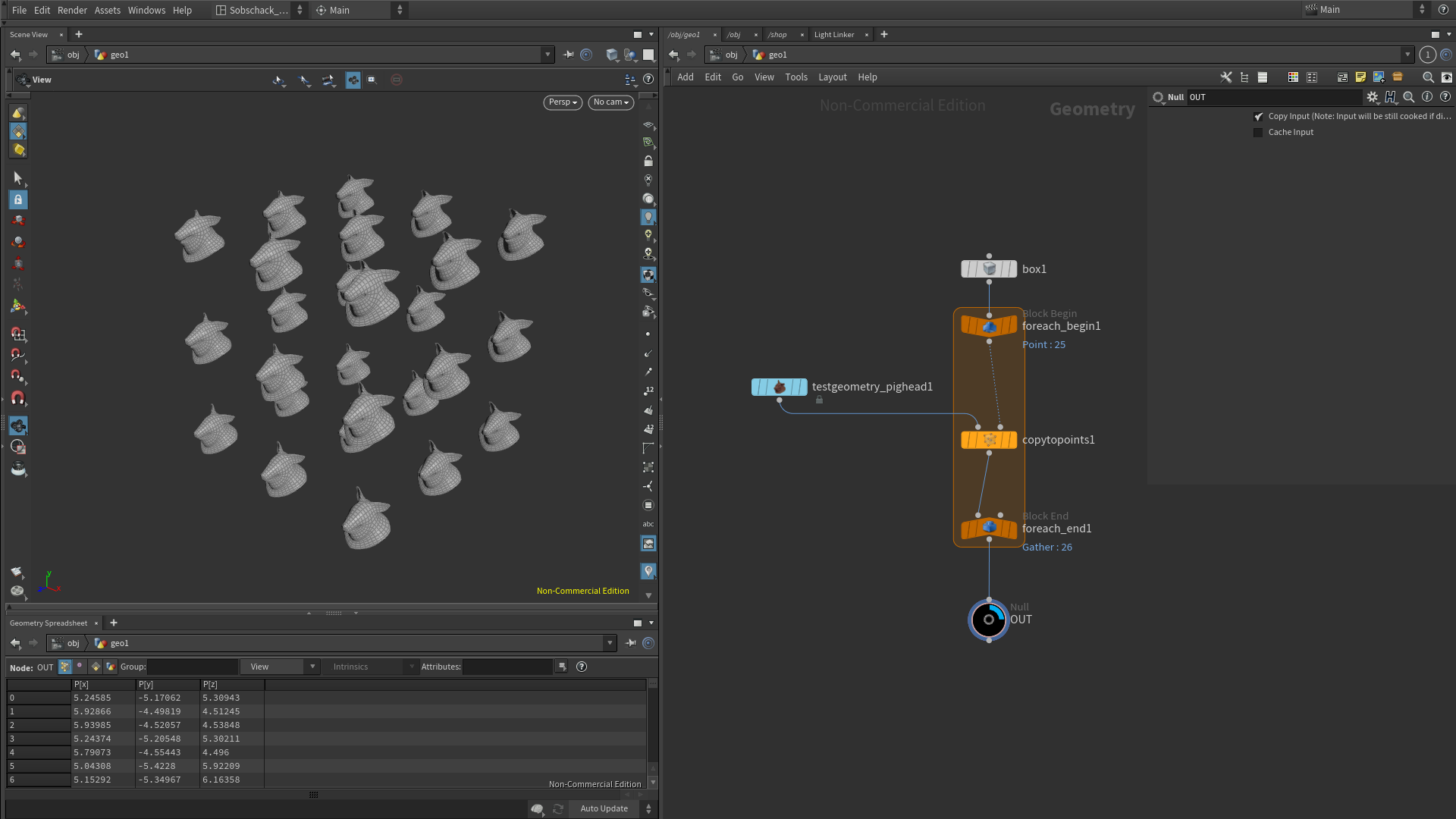
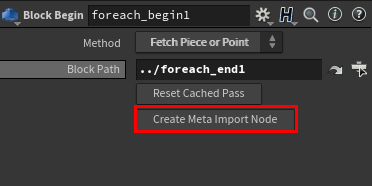
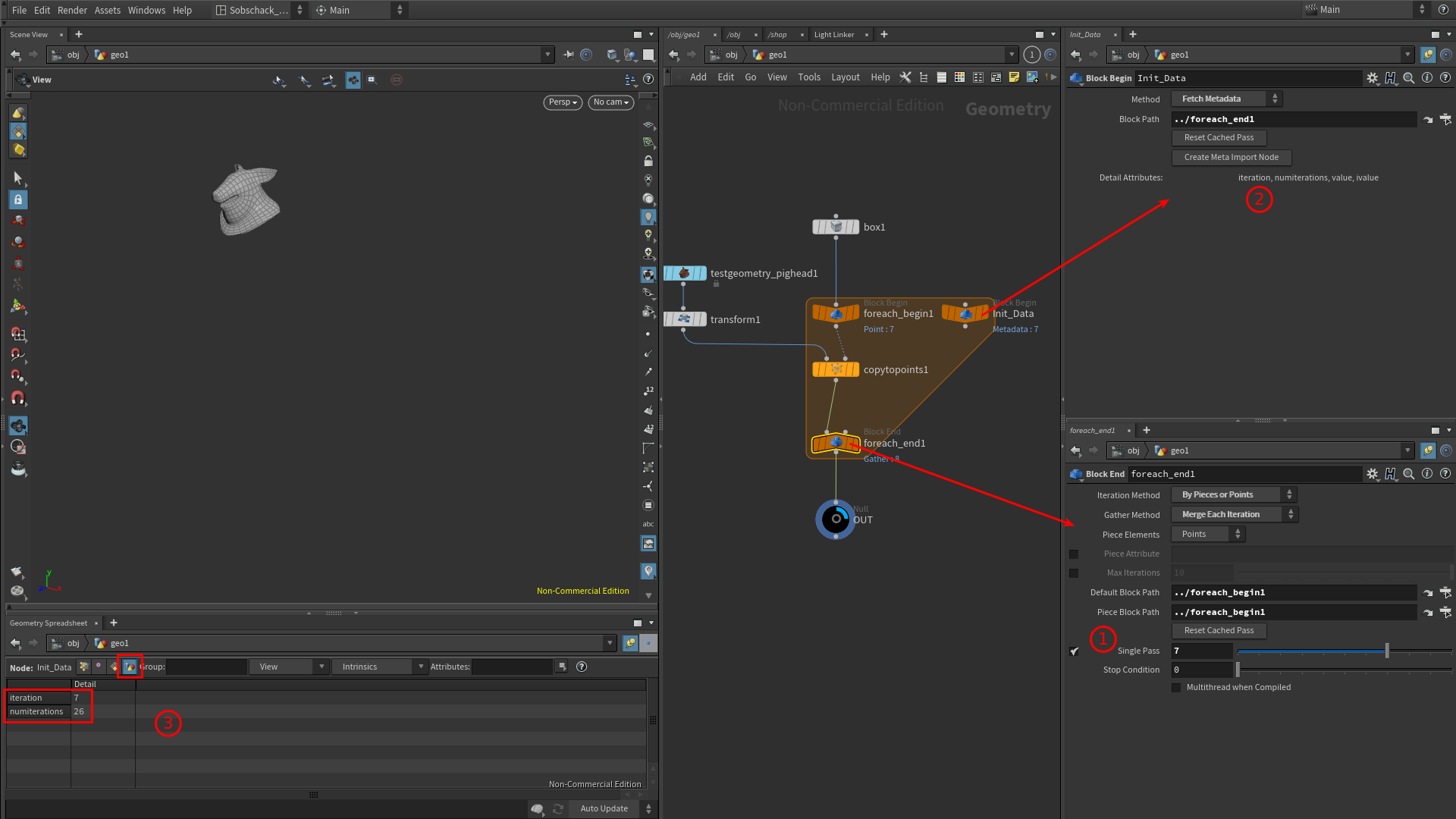
Ensuite, nous allons créer un node de Metadata en sélectionnant le node For-each Begin, puis en cliquant sur Create Meta Import Node :
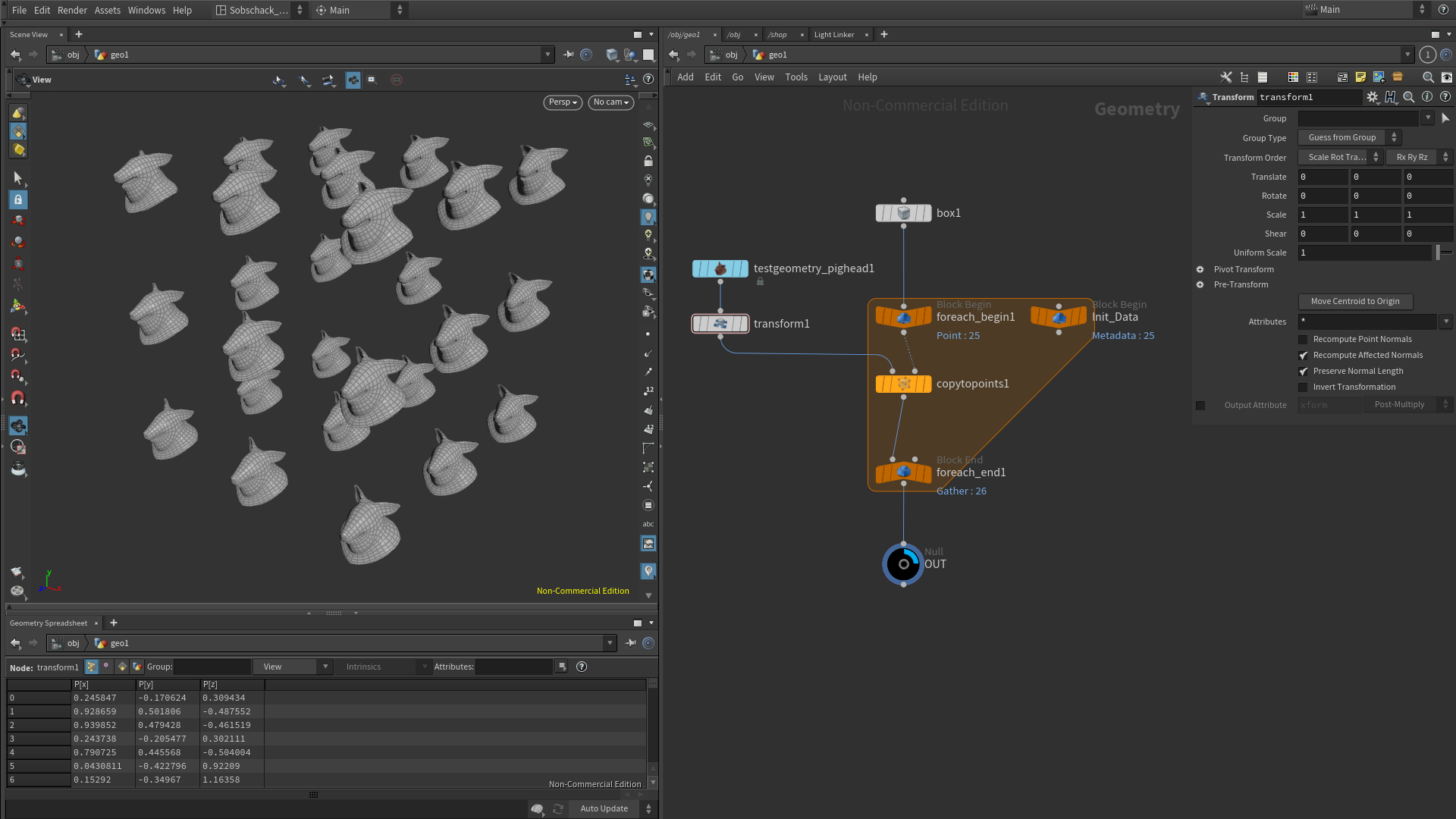
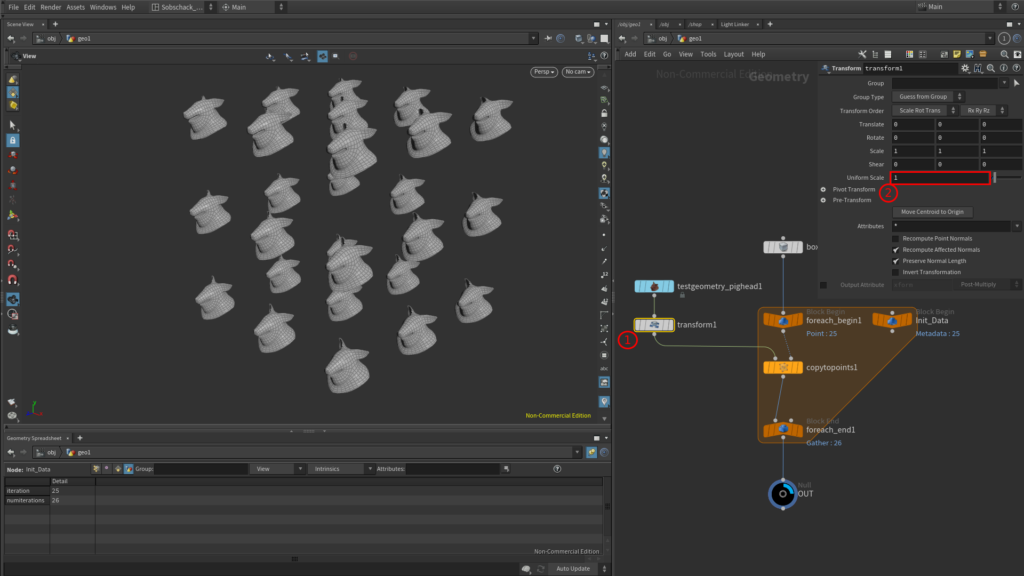
On rajoute également un node de Transform sous le Pig Head, c’est ce Node qui nous servira à générer des paramètres aléatoires dans la boucle :
Focus sur le Node Metadata
Avant de continuer, posons nous pour bien comprendre ce Node de Metadata dans notre boucle For-each :
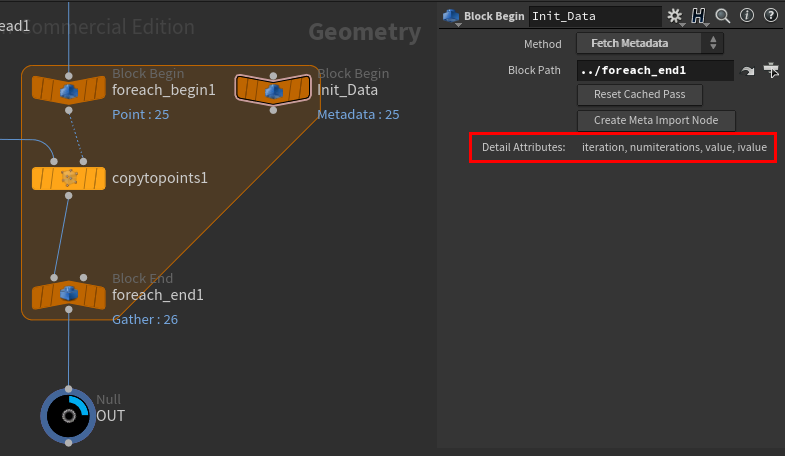
Ce node, crée tout simplement des attributs de class detail pour chaque itération dans la boucle. Nous allons nous concentrer sur l’attribut nommé « iteration ».
Cet attribut ne fait qu’un chose : changer de valeur à chaque itérations :
Cette capacité va nous permettre de générer un nombre aléatoire différent pour chacune des itérations dans la boucle grâce à la fonction rand(). Le fait que cet attribut change pour chaque itérations vous nous garantir de générer un nombre aléatoire tout le temps différent.
En effet, rappelez vous que nous sommes dans une boucle « For-each » ce qui signifie littéralement « Pour chaque » : « Pour chaque point », « Pour chaque primitive ». Tout ce qui rentre dans une telle boucle est traité seul, isolé, ce qui fait que par exemple @ptnum ou @primum seront toujours égale à 0 pour chaque itérations.
Si nous utilisons la fonction rand() sur 0, elle retournera toujours la même valeur, a dieu tout aléatoire.
Elaboration de l’expression aléatoire.
Nous allons commencer à injecter une échelle random pour chaque copies de notre Pig Head, l’expression sera donc copiée dans le paramètre Uniform Scale du transform qui suit notre Pig Head (cela fonctionnerait aussi avec le paramètre Uniform Scale du Pig Head directement) :
Pour faciliter l’édition de notre expression, cliquer dans la case du paramètre Uniform Scale puis faites Alt+E.
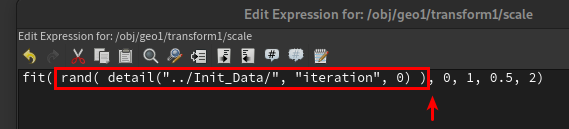
Nous allons commencer par aller chercher notre attribut « iteration » avec la fonction detail()
detail("../Init_Data/", "iteration", 0)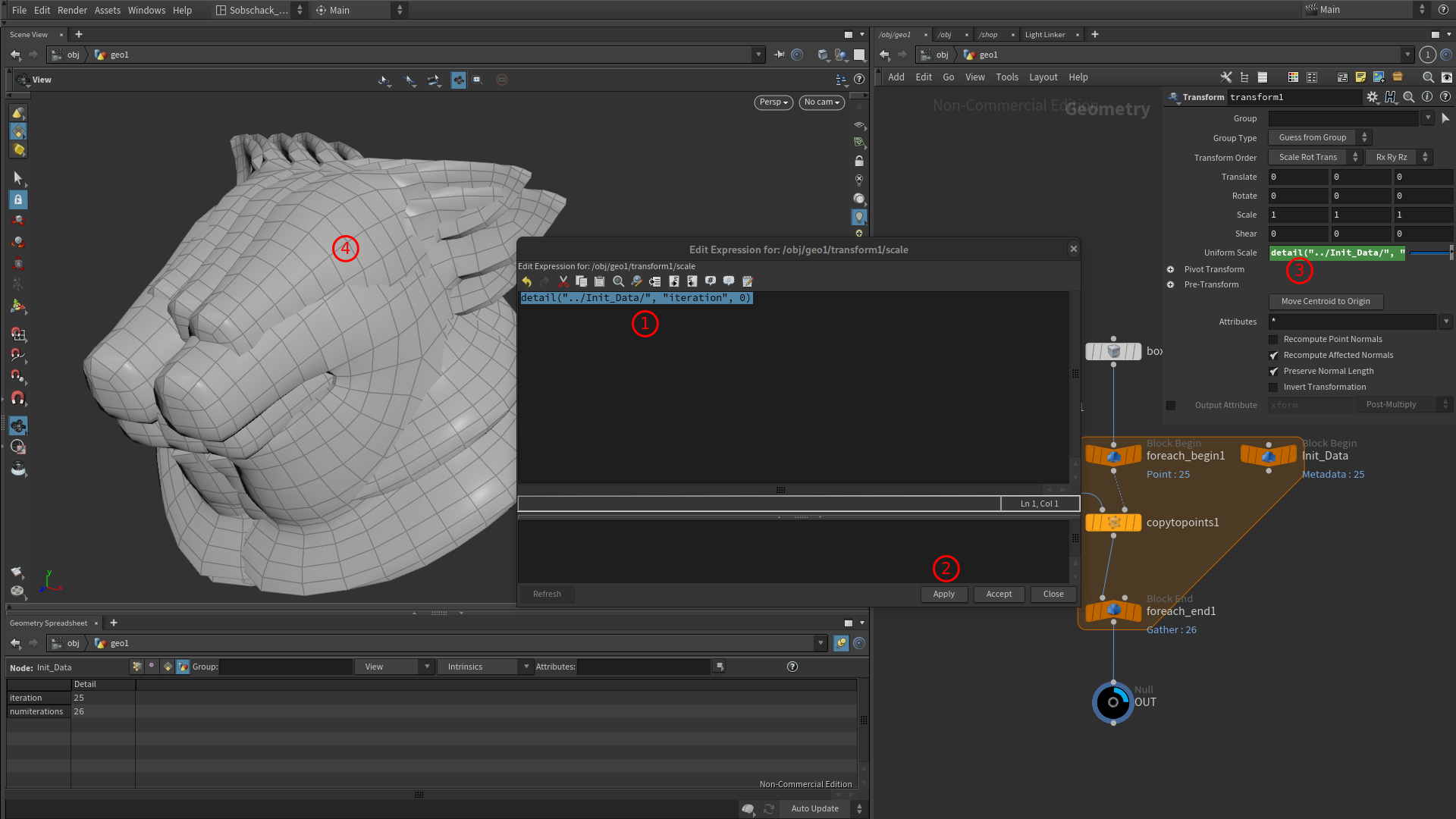
La valeur du paramètre Unifrom Scale prend alors une des valeurs de l’attribut « iteration », donc quelque chose compris entre 1 et 26 pour le moment.
Continuons pour améliorer notre expression : en effet pour le moment l’itération 0 un echelle de 0, la 3 une échelle de 3 etc. C’est tout sauf aléatoire…
Il est temps d’introduire de l’aléatoire grâce à la fonction rand(), bien entendu, l’argument de notre fonction rand() est TOUTE notre précédente expression :
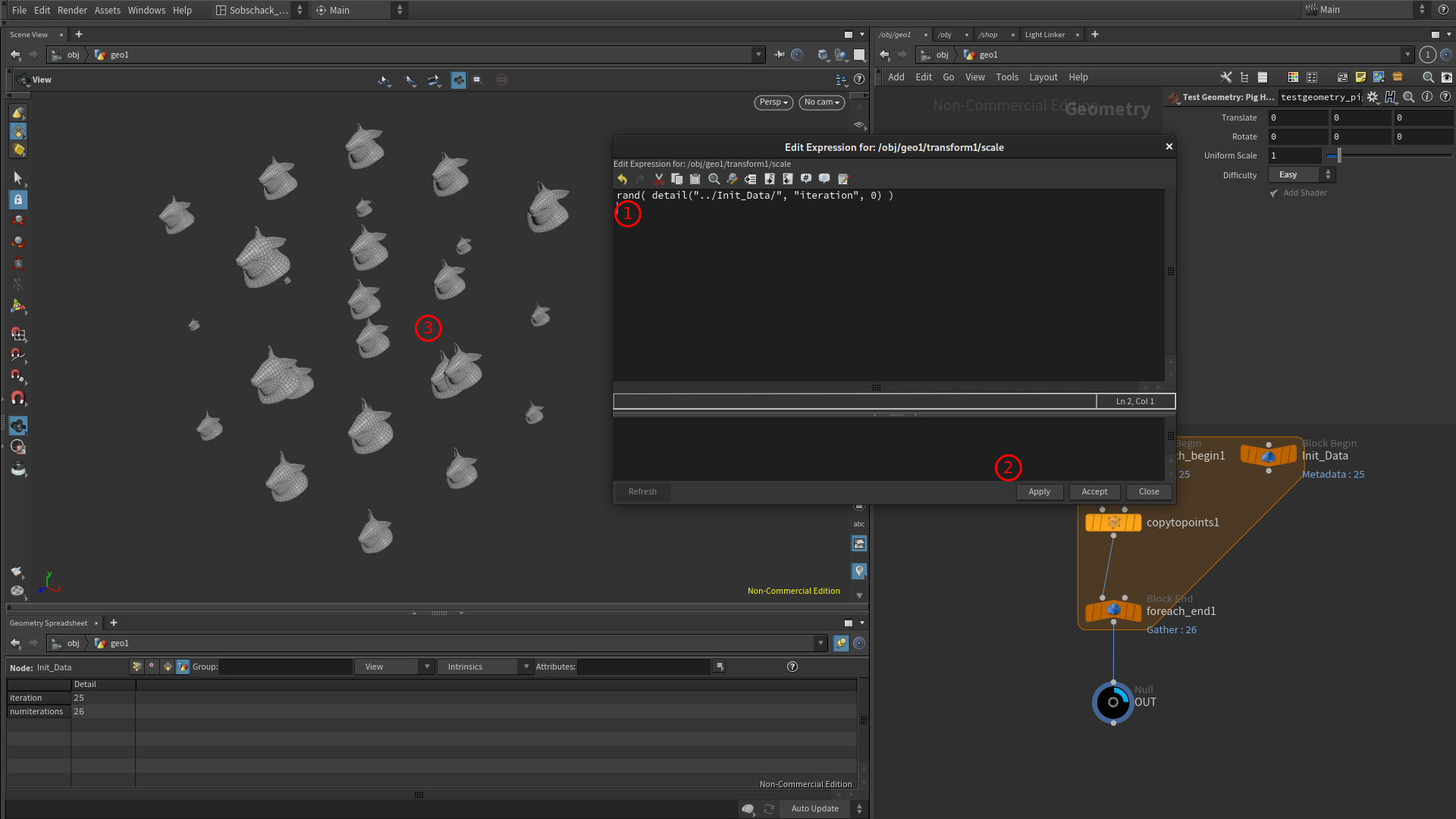
Bon, ça devient cool ! Reste une dernière chose : contrôler notre plage d’échelles pour avoir la main sur la taille des éléments.
C’est maintenant que nous introduisons la fonction fit(). J’opte pour une échelle comprise entre 0.5 et 2 :

Et voila ! Terminé pour le paramètre d’échelle aléatoire dans notre boucle For-each.
Note : Attention à cette virgule dans la fonction fit(), elle est traître est génère souvent des erreurs de frappe. En effet, la valeur que l’on souhaite fitter est toute notre expression précédent, si bien qu’il ne faut pas oublier de la faire suivre d’une virgule…
Aller plus loin
Bien entendu, vous pouvez introduire du random sur d’autre paramètres, voila par exemple, les expressions sur j’ai rentrée en Rotate X, Y et Z dans le Transform :
fit( rand( detail("../Init_Data/", "iteration", 0) ), 0, 1, -360, 360)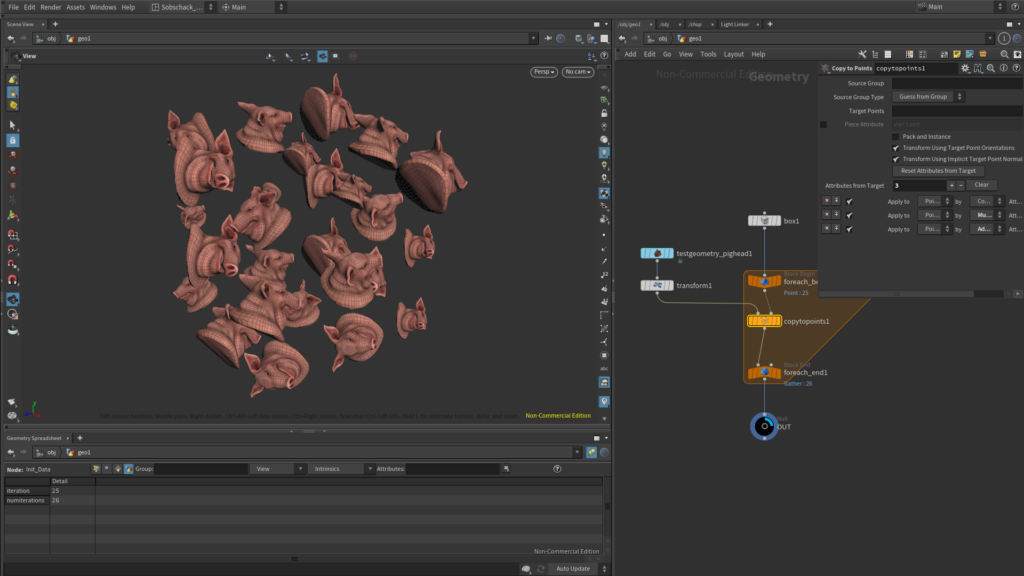
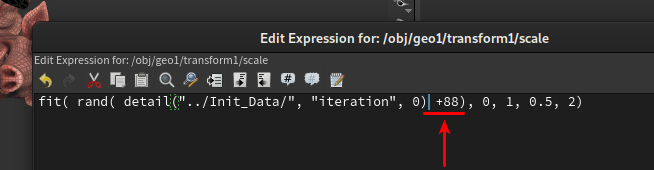
Vous pouvez également rajouter un paramètre de seed pour changer les valeurs aléatoires dans une fonction rand(). La syntaxe est celle ci :
rand(value+55)
or
rand(value*892)La valeur du nombre n’étant pas important, a chaque nombre (int ou float) un nouveau seed est calculé.
Dans un prochain article, je vous ferai voir comme créer une petite interface (sans HDA) pour gérer des seeds avec des paramètres :
0 commentaire